What is SEO?
SEO can be broken down into four basic components you should be aware of:
Search Engine Access: this is all the stuff you need to do to make sure the search engines can get to all the parts of your website you want them looking at.
Search Engine Indexing: Once search engines get to your content, you want them to be able to read it properly.
Search Engine Authority: You want to make sure the content you’re creating is authoritative. That means using the same phrases your target customers use and giving them the best experience possible.
Search Engine Popularity: Search engines use backlinks as a ranking factor – meaning they’ll look at how many quality websites are linking back to you. So the more popular your website, the higher the chance it has to rank well.
Essentially SEO is all about getting someone like Homer in front of what he truly wants. Donuts. YOUR donuts.

Developers are mostly involved with Access and Indexing.
Here’s how we break it down.
Search engine access
Search engines are incredibly smart, but since the internet is huge, trying to find everything and catalog it is extremely difficult. So part of SEO is to help search engines find and access as much as your website as you want to be indexed.
How search engines access websites
Search Engines crawl the web finding websites to save to their index to later show their users on the off chance it will help solve a user’s query.
The crawling process begins with a list of web addresses from past crawls and sitemaps provided by website owners. As Google’s crawlers visit these websites, they use links on those sites to discover other pages. Their software pays special attention to new sites, changes to existing sites and dead links.
These changes are registered in a few ways:
- Webmasters can leverage google search console to request indexing of individual URL’s
- Webmasters can update XML sitemaps with new URLs
- Webmasters can provide detailed instructions about how to process pages on their sites
PRO TIP: XML Sitemaps are an SEO’s best friend for a few reasons. Multiple sitemaps allow you to organize your web pages into product groupings, categories, content types, sales funnel positions, test groupings, and so much more.
PRO TIP: Make sure to do update modification times in the XML sitemap only when substantial changes to those web pages are made.
PRO TIP: <Priority> doesn’t matter to Google in particular, they ignore it.
A quick note on robots.txt files
Please don’t leave these blank. Please. At the very least include a link to the XML index file in the robots.txt file. But the robots.txt file is the fastest and (often) easiest way to limit what pages get crawled.
Common example: A blank robots.txt file exists on a site where the SEO team and the Paid Marketing team both have pages that serve the same purpose. Both are by default indexable, which creates a duplicate content issue. If the robots.txt file were to have a “disallow” command on the subfolder level for the paid marketing versions of the web page, then no duplication issue exists, saving everyone headaches.
Search engine indexing
The key to remember here is that search engines are actively trying to read your site and request and render content similar to browsers. So step one in optimizing your website for Google and other search engines is to make sure it’s “crawlable.” Meaning they can not only access the individual web pages, but they can read what’s on the page.
Here’s the tricky part. Google and Bing still have a hard time indexing certain codebases like Ajax, JavaScript, and Jquery.
But Google claims they can crawl and index content served via client-side, so what’s the problem?
Yes, Google has made that claim. And yes, they technically can crawl, index, and render client-side JavaScript, but it’s inconsistent. In a recent test we ran, we updated the metadata of a client’s core web pages (meaning every subpage after domain.com, not including subdomains). We found Google was only able to index and render the content changes on 50% of the URLs whose content changed. This customer currently renders all content with client-side JavaScript.
How Googlebot indexes and renders JavaScript websites:
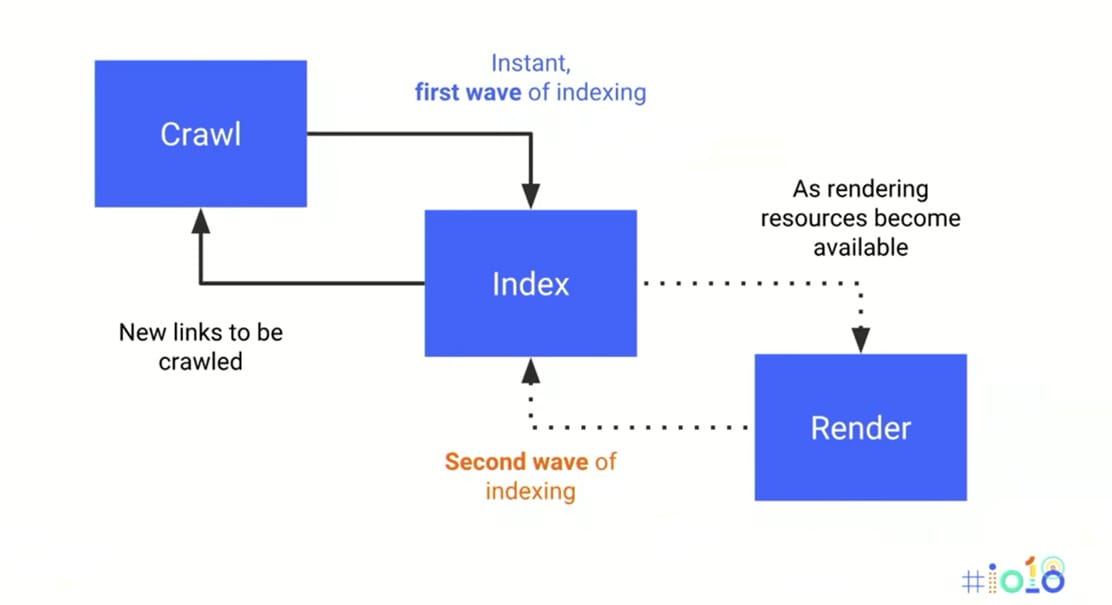
- Googlebot downloads an HTML file
- Googlebot downloads the CSS and JavaScript files
- Googlebot has to use the Google Web Rendering Service (a part of the Caffeine Indexer) to parse, compile, and execute a JS code
- WRS fetches the data from external APIs, from the database, etc.
- Finally, the indexer can index the content
- Now Google can discover new links and add it to the Googlebot’s crawling queue
Parsing, compiling, and running JS files is very time-consuming. In the case of a JavaScript-rich website, Google has to wait until all the steps are done before it can index the content. The rendering process is not the only thing that is slower. It also refers to a process of discovering new links.
Here’s the kicker: The rendering of JavaScript-powered websites in Google search is deferred until Googlebot has resources available to process that content. That can take up to two weeks.
Why SEOs prefer server-side rendering
Server-side rendering can be a bit faster at the initial request, quite simply because it doesn’t require as many round trips to the server. JavaScript requires the search engine to spend longer rendering, which means additional electricity expended, increased CPU demand, as well as dramatically slowing down the standard rendering process. For server-side rendering, all of the HTML content is present in the source code. This lets search engines request, crawl and index it immediately, resulting in improved page speed performance (a major ranking factor), and all impactful content being indexed and cached. This consistently leads to improved ranking in search results.
Is server-side rendering the only way to go?
SEO’s will always first recommend server-side rendering. But making the switch from client-side to server-side is cumbersome and time-consuming.
But server-side rendering is getting more and more traction thanks to React and its built-in server-side hydration feature. However, it’s not the only solution to deliver a fast experience to the user and allow search engines to quickly index content. Pre-rendering is also a good strategy.
You could leverage pre-rendering with a solution like Preact. It has its own CLI that allows you to compile all pre-selected routes so you can store a fully populated HTML file to a static server. This lets you deliver a super-fast experience to the user, thanks to the Preact/React hydration function, without the need for Node.js.
Another option is to use prerender.io, which renders your JavaScript in a browser, saves the static HTML, and returns that to the crawlers. The Prerender.io middleware that you install on your server will check each request to see if it’s a request from a crawler (like GoogleBot). And if it is a request from a crawler, the middleware will send a request to Prerender.io for the static HTML of that page. And if not, the request will continue on to your normal server routes. This is a great option as crawlers will never know you’re using prerender.io (nor would they care), and you’re able to send the user and crawlers the most important information in static form, while maintaining the flexibility that comes with client-side rendering.
Let’s talk about page speed for a second
Page speed is a major ranking factor among search engines. It also affects the user experience, and can affect revenue. The main goal is to get any page to load in one second.
PRO TIP: Google’s PageSpeed Insights Speed Score incorporates data from CrUX (Chrome User Experience Report) and reports on two important speed metrics: First Contentful Paint (FCP) and DOMContentLoaded (DCL), so that’s what the majority of SEOs focus on when measuring page speed.
Here are some simple (albeit time-consuming, depending on how much code you have to minify) ways to improve page speed:
- Minify your code: If you optimize your code by removing spaces, commas, and other unnecessary characters, you can improve your page speed.
- Reduce redirects: Each time a page redirects to another page, your visitor faces additional time waiting for the HTTP request-response cycle to complete, which will increase page load time.
- Remove render-blocking JavaScript:. If a browser (or GoogleBot) encounters a script while rendering a page, it has to stop and execute it before it can continue. An easy way to fix this is by adding the tag “async” to your JavaScript code to asynchronously load any code not needed at initial page load.
- Leverage browser caching: Browsers can cache a lot of information so that when a visitor comes back to your site, the browser doesn’t have to reload the entire page.
- Use a CDN: Users will have a faster and more reliable experience loading your site if you were to leverage multiple, geographically diverse data centers.
- Optimize Images: This is the most common culprit for slow pages. Make sure they are compressed for the web.
The nail in the coffin…
Ultimately SEO is all about getting your content in front of the user. Because there are complexities in any major code changes (such as trying to shift from client-side to server-side), it’s important to keep a creative and open mind.
Lastly, because SEO is does not quickly generate results, it often gets derailed or postponed due to other revenue-generating priorities. Keep in mind that SEO is like drops in a bucket, and eventually that bucket overfloweth. Companies that have engineers invested in SEO see significantly more consistent revenue than those that deprioritize it.